* LAG함수, LEAD함수, LISTAGG함수를 살펴보자
| LAG 함수
LAG함수는 현재 행에서 offset 이전 행의 value_expr을 반환한다. offset은 행 기준이며 기본 값은 1이다. default에 이전 행이 없을 경우 반환할 값을 지정할 수 있다. default의 기본값은 널이다.
LAG(value_expr[, offset [, default]])[IGNORE NULLS] OVER([query_partition_clause] order_by_clause)ex 1 )
SELECT hiredate, sal
, LAG(sal) OVER(ORDER BY hiredate) AS c1
, LAG(sal,3) OVER(ORDER BY hiredate) AS c2
FROM emp
WHERE deptno = 30
ORDER BY 1;
- 81/02/20 의 SAL 1600을 LAG 함수를 이용하여 바로 앞 행의 SAL값을 81/02/22 의 C1에서 가져오는 것을 확인할 수 있다. 그리고 81/02/20의 C1은 앞 행에서 가져올 값이 없으므로 Default 값인 NULL 을 가져온다.
ex 2 )
SELECT ename, hiredate, comm
,① LAG(comm,2,999) IGNORE NULLS OVER(ORDER BY hiredate) AS C1
FROM emp
WHERE deptno = 30
ORDER BY 2;
① LAG(comm,2,999) IGNORE NULLS OVER(ORDER BY hiredate) AS C1 : 2개 앞 행의 값을 가져오는데, 2개 앞 행의 값이 없을 경우 default값으로 999를 가져온다. IGNORE NULLS 를 사용하면서 NULL 에 해당하는 행은 건너뛰게 된다. 따라서 TURNER의 C1값은 NULL을 건너뛰어서 2개 행 앞인 300 값을 가져오게 되고, MARTIN은 0, NULL건너뛰고 500 값을 가져오게 된다.
ex 3 )
SELECT sal, comm
,① NVL(comm, LAG(comm) IGNORE NULLS OVER(ORDER BY sal, empno)) AS comm_n
FROM emp
WHERE deptno IN (10, 30)
ORDER BY sal, empno;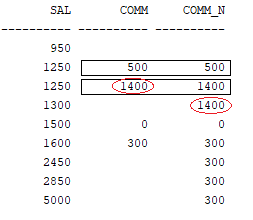
① NVL(comm, LAG(comm) IGNORE NULLS OVER(ORDER BY sal, empno)) AS comm_n : NVL 함수안에 LAG 함수를 써서 comm의 값이 있을 땐 그대로 comm값을 받고, null일 때는 LAG(comm) IGNORE NULLS OVER(ORDER BY sal, empno) 값을 받도록 한다.
| LEAD 함수
LEAD 함수는 현재 행에서 offset 이후 행의 value_expr을 반환한다.
LEAD(value_expr [, offset [, default]])[IGNORE NULLS] OVER([query_partition_clause] order _by_clause)
ex 1 )
SELECT hiredate, sal
, LEAD(sal) OVER(ORDER BY hiredate) AS c1
, LEAD(sal, 3) OVER(ORDER BY hiredate) AS c2
FROM emp
WHERE deptno = 30
ORDER BY hiredate;
- LEAD는 LAG와 반대 개념이라고 생각하면 이해가 편하다. 따라서 뒤 행의 SAL 값을 가져온다고 생각하면 된다.
ex 2 )
SELECT hiredate, sal
, LAG(sal) OVER(ORDER BY hiredate DESC) AS c1
, LEAD(sal) OVER(ORDER BY hiredate) AS c2
FROM emp
WHERE deptno = 30
ORDER BY hiredate;
* LAG 함수와 LEAD 함수는 반대로 동작하므로 정렬 값을 반대로 했을 때 같은 결과를 얻을 수 있다. 그러나 분석함수의 정렬 값이 고유하지 않으면 값이 무작위로 변경될 수 있다.
ex 3 )
-- 1)
SELECT empno, ename, sal, comm
, LEAD(comm) OVER(ORDER BY sal) AS c1
FROM emp
WHERE deptno = 30
ORDER BY 3, 1;
-- 2)
SELECT empno, ename, sal, comm
, LEAD(comm) OVER(ORDER BY sal) AS c1
FROM emp
WHERE deptno = 30
ORDER BY 3, 2;
* ORDER BY 절을 변경했을 뿐인데 c1 값이 변경되었다. 위 쿼리에서 분석함수의 정렬 값을 고유하게 만들어준다면 ORDER BY 절에 따라 결과는 변경되지 않는다.
-- 1)
SELECT empno, ename, sal, comm
, LEAD(comm) OVER(ORDER BY sal, empno) AS c1
FROM emp
WHERE deptno = 30
ORDER BY 3, 1;
-- 2)
SELECT empno, ename, sal, comm
, LEAD(comm) OVER(ORDER BY sal, empno) AS c1
FROM emp
WHERE deptno = 30
ORDER BY 3, 2;
| LISTAGG 함수
LISTAGG 함수는 measure_expr를 order_by_clause로 정렬한 후 delimiter로 구분하여 연결한 값을 반환한다. delimiter의 기본값은 널이다.
LISTAGG(measure_expr [, 'delimiter'][listagg_overflow_clause]) WITHIN GROUP(order_by_clause)[OVER query_partition_clause]
ex )
SELECT job, ename
,① LISTAGG(ename, ',') WITHIN GROUP(ORDER BY ename) OVER(PARTITION BY job) AS c1
FROM emp
WHERE deptno = 30
ORDER BY job, ename;
① LISTAGG(ename, ',') WITHIN GROUP(ORDER BY ename) OVER(PARTITION BY job) AS c1 : job별로 ename 열 기준 오름차순으로 정렬 한 그룹에서 ename을 ',' 로 구분하여 나열한다.