데이터를 찾는 방법
오라클에서 데이터를 찾는 방법은 아래와 같이 세 가지가 있다.
- 테이블 전체 읽기(TABLE ACCESS FULL)
- 인덱스를 이용한 찾기(INDEX RANGE SCAN & TABLE ACCESS BY INDEX ROWID)
- ROWID를 이용한 직접 찾기(TABLE ACCESS BY INDEX ROWID)
'테이블 전체 읽기(TABLE ACCESS FULL)'는 테이블의 데이터 블록을 차례대로 모두 읽으면서 필요한 데 이터를 찾는 방법이다.
인덱스를 이용한 찾기(INDEX RANGE SCAN & TABLE ACCESS BY INDEX ROWID)'는 인덱스를 이용 해 필요한 데이터만 찾는 방법이다. 이 방법은 필요에 따라 'TABLE ACCESS BY INDEX ROWID'작업을 동반한다.
마지막으로 'ROWID를 이용한 직접 찾기(TABLE ACCESS BY INDEX ROWID)'는 테이블의 레코드 주소 인 ROWID를 조건 값으로 사용해 필요한 데이터를 직접 찾아가는 방법이다.
데이터를 찾는 방법 - 테이블 전체 읽기
테이블 전체 읽기는 실행계획에 'TABLE ACCESS FULL'로 표현된다. 편의상 '테이블 풀 스캔(TABLE FULL SCAN)'이나 '풀 스캔(FULL SCAN)'이란 용어를 사용하기도 한다.
데이터 전체 읽기는 찾고자 하는 조건에 활용할 인덱스가 없거나 인덱스보다 테이블 전체를 읽는 것이 더 효율적이라고 판단될 때 사용하는 방법이다.
오라클에서 데이터가 테이블에 저장될 때는 특정 순서를 갖지 않는다. 예를 들어, ORD_YMD가 '20170110'인 데이터가 저장될 때 물리적으로 '20170109' 다음에 위치한다고 장담할 수 없다.
WHERE 조건절에 사용된 컬럼에 적절한 인덱스가 없다면, '테이블 전체 읽기'만이 원하는 데이터를 찾을 수 있는 유일한 방법이다.
예제 ) TABLE ACCESS FULL을 사용하는 SQL
SELECT /*+ GATHER_PLAN_STATISTICS */
T1.CUS_ID, COUNT(*) ORD_CNT
FROM T_ORD_BIG T1
WHERE T1.ORD_YMD = '20170316'
GROUP BY T1.CUS_ID
ORDER BY T1.CUS_ID;
실행계획의 2번 오퍼레이션에 'TABLE ACCESS FULL'이 있는 것을 알 수 있다.
'TABLE ACCESS FULL'은 테이블 블록 전체를 읽는다. 그러므로 테이블이 클수록 오래 걸린다. 만약에 천 만 건의 데이터를 가진 테이블에서 찾고자 하는 데이터가 한 건이라면, 천만 건을 모두 읽어야 하는 엄청 난 비효율이 발생한다. 이런 경우에는 인덱스를 사용해 데이터를 찾아내는 것이 효율적이다. 하지만 천 만 건의 데이터를 가진 테이블에서 찾아야 하는 데이터가 백만 건 정도 된다면 인덱스를 사용하는 것보 다 'TABLE ACCESS FULL'이 더 효율적일 수 있다.
데이터를 찾는 방법 - 인덱스를 이용한 찾기
인덱스를 이용하면 필요한 데이터만 정확히 찾아낼 수 있다.
인덱스로 데이터를 찾는 방법은 'INDEX RANGE SCAN', 'INDEX SKIP SCAN', 'INDEX FULL SCAN'과 같이 다양하다. 이 중 가장 기본은 'INDEX RANGE SCAN'이다.
인덱스는 다음 그림과 같이 삼각형으로 간략하게 표현할 수 있다. 삼각형의 꼭짓점은 루트 블록이고 밑 변은 리프 블록이다.

인덱스를 이용해 데이터를 찾는 과정을 전체적으로 그려보면 다음과 같다.

1. 루트에서 리프로 : 검색 조건에 해당하는 첫 번째 리프 블록을 찾는 과정
2. 리프 블록 스캔 : 찾아낸 지점부터 리프 블록을 차례대로 읽어 가는 과정
3. 테이블 접근 : 리프 블록을 스캔하면서 필요에 따라 테이블에 접근하는 과정
위 설명에서 1번과 2번을 묶어서 'INDEX RANGE SCAN'이라고 한다. 'INDEX RANGE SCAN'은 필요에 따 라 테이블에 접근하는 'TABLE ACCESS BY INDEX ROWID' 작업을 동반한다.
인덱스를 이용해 데이터를 찾는 과정은 다음과 같다.
(1) 루트에서 리프로(리프 블록 찾기)
루트 블록에서 주어진 조건이 저장된 리프 블록을 찾아가는 과정이다. 이 과정은 부하가 없다고 생각할 정도로 매우 빠르게 이루어진다. 탐색방법은 이전에 설명해준 것과 동일하다.
(2) 리프 블록 스캔(RANGE SCAN)
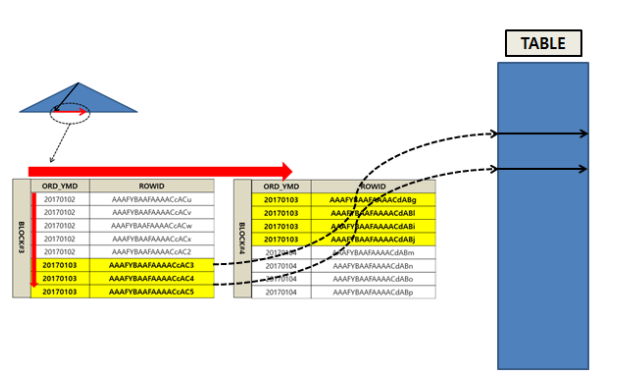
'리프 블록 스캔(RANGE SCAN)'을 확대하면 다음 그림과 같다. 그림은 'ORD_YMD'로 구성된 인덱스의 리프 블록이다. 리프 블록은 인덱스의 키 컬럼인 ORD_YMD 값의 순으로 정렬되어 있다. 그림은 ORD_YMD가 '20170103'인 데이터를 검색하고 있다. '루트에서 리프로' 과정에서 '20170103'이 최초로 저장된 3번 리프 블록(BLOCK#3)을 찾아냈다고 가정하면, 3번 리프 블록을 찾아낸 후에는 리프 블록 내 의 데이터를 차례대로 읽어 나간다. 그러다 ORD_YMD가 '20170103'보다 큰 데이터를 만날 때 까지의 과 정을 '리프 블록 스캔'이라고 한다. 여기서는 두 개의 블록을 읽었다.

(3) 테이블 접근(TABLE ACCESS BY INDEX ROWID)
'리프 블록 스캔' 과정에서는 필요에 따라 테이블 접근을 한다. 이는 인덱스 리프 블록의 ROWID 값을 참 조해 테이블의 데이터를 찾아가는 과정이다.
이 과정은 테이블에서 필요한 값이 있을 때만 일어난다. 만약에 ORD_YMD 값만 사용해 SQL을 처리할 수 있다면 이 과정은 생략된다.
ORD_YMD 컬럼에 인덱스를 구성한 후에, ORD_YMD가 '20170316'인 데이터를 카운트해보자.
예제 ) INDEX RANGE SCAN을 사용하는 SQL
CREATE INDEX X_T_ORD_BIG_1 ON T_ORD_BIG(ORD_YMD);
SELECT /*+ GATHER_PLAN_STATISTICS INDEX(T1 X_T_ORD_BIG_1) */
T1.CUS_ID, COUNT(*) ORD_CNT
FROM T_ORD_BIG T1
WHERE T1.ORD_YMD = '20170316'
GROUP BY T1.CUS_ID
ORDER BY T1.CUS_ID;
SQL의 3번 라인을 보면, 'INDEX(T1 X_T_ORD_BIG_1)' 힌트를 사용해 인덱스를 사용하도록 강제하고 있 다. 힌트는 SQL의 처리방법(실행계획)만 변경할 뿐 실행 결과에는 절대 영향을 주지 않는다.

인덱스를 이용한 실행계획을 확인해 보면 물리적IO(Reads)와 논리적IO(Buffer)가 테이블 전체(TABLE ACCESS FULL)를 읽을 때보다 줄어들었다.
실행계획에 'INDEX RANGE SCAN'과 'TABLE ACCESS BY INDEX ROWID' 작업이 있다. WHERE 조건에 맞 는 데이터를 찾기 위해 'INDEX RANGE SCAN'을 사용했고, 인덱스에 없는 'CUS_ID' 값을 가져오기 위해 'TABLE ACCESS BY INDEX ROWID'작업까지 수행한 것이다.
'INDEX' 카테고리의 다른 글
| INDEX의 기본 개념_INDEX RANGE SCAN VS. TABLE ACCESS FULL (0) | 2021.07.03 |
|---|---|
| INDEX의 기본 개념_B*트리 구조와 탐색 방법 (0) | 2021.07.03 |
| INDEX의 기본 개념_인덱스 종류 (0) | 2021.07.03 |
| INDEX의 기본 개념_인덱스(INDEX)란 ? (0) | 2021.07.03 |