728x90
320x100
1. Raid 란?
- Redundant Array of Independent Disk (독립된 디스크의 복수 배열)
- Redundant Array of Inexpensive Disk (저렴한 디스크의 복수 배열)
- Raid는 여러개의 디스크를 묶어 하나의 디스크처럼 사용하는 기술입니다
- Raid는 컴퓨터를 구성하는 여러 부품 중 기계적인 특성 때문에 상대적으로 속도가 느린 하드디스크를 보완하기 위해 만든 기술입니다.
- Raid를 구성하는 디스크의 개수가 같아도, Raid의 구성 방식에 따라 성능, 용량이 바뀌게 되며, 이 구성 방식을 Raid level 이라고 부릅니다
2. Raid 를 사용했을 때 기대되는 효과
- 대용량의 단일 볼륨을 사용하는 효과
- 디스크 I/O 병렬화로 인한 성능 향상(Raid 0, Raid 5, Raid 6 등)
- 데이터 복제로 인한 안정성 향상(Raid 1 등)
3. Standard Raid level
- Raid level은 0~6까지 존재하며, 최근 출시되는 Raid 컨트롤러에서 사용가능한 Raid level은 Raid 0, Raid 1, Raid 5, Raid 6 입니다
- Raid를 구성하는 디스크의 종류와 크기는 같다고 가정하도록 하며, 실제로도 같은 크기, 종류의 디스크를 사용하는 것을 권장합니다.
- 성능의 경우 Raid 컨트롤러의 연산으로 인한 성능 저하는 제외하고, Sequential I/O 시만 가정하겠습니다.
- Raid를 구성하는 디스크의 개수는 N으로 표현하겠습니다.
* 이미지 및 표 출처 -https://en.wikipedia.org/wiki/Standard_RAID_levels
Standard RAID levels - Wikipedia
From Wikipedia, the free encyclopedia Any of a set of standard configurations of Redundant Arrays of Independent Disks In computer storage, the standard RAID levels comprise a basic set of RAID ("redundant array of independent disks" or "redundant array of
en.wikipedia.org
1) Raid 0

- Stiping(스트라이핑) 이라고 부르는 방식
- Raid 0을 구성하기 위해서는 최소 2개 디스크 필요( min(N) ==2 )
- Raid를 구성하는 모든 디스크에 데이터를 분할 저장
- 전체 디스크를 모두 동시에 사용하기 때문에 성능은 단일 디스크 성능의 N배 입니다(마찬가지로 용량 역시 단일 디스크 용량의 N배가 됩니다.)
- 하나의 디스크라도 문제가 발생할 경우 전체 Raid가 깨지는 이슈가 발생합니다.(즉, 안정성은 1/N으로 줄어든다.)
- 성능,용량 과 안정성이 반비례(trade-off) 관계
- 실제 서버 환경에서는 거의 사용하지 않는다고 합니다.
2) Raid 1
- Mirroring(미러링) 이라고 부르는 방식
- Raid 1을 구성하기 위해서는 최소 2개의 디스크 필요( min(N) ==2 )
- Raid 컨트롤러에 따라서 2개의 디스크로만 구성 가능할 수도, 그 이상의 개수를 사용하여 구성할 수도 있다.
- Raid 1은 모든 디스크에 데이터를 복제하여 기록한다.(즉, 동일한 데이터를 N개로 복제하여 각 디스크에 저장한다.)
- 여러 개의 디스크로 Raid를 구성해도, 실제 사용 가능한 용량은 단일 디스크이 용량과 동일합니다
- Write 시에는 데이터를 복제하여 N개 디스크에 기록하기 때문에, Raid 컨트롤러가 복제, 연산하는 시간을 감안하면 단일 디스크 Write성능보다 낮게 나올 수 있다.(반대로, Read 시에는 전체 디스크에서 읽어 올 수 있기 때문에 단일 디스크의 N배 성능이 나옴.)
- Raid 1의 최대 강점은 안정성이 높다.
- N-1개의 디스크가 고장나도 데이터 사용이 가능하다.(단, 이런 상황이 발생했을 때는 빠르게 데이터 백업을 해줘야한다.)
- 안정성이 중요한 시스템에서 사용할 수 있으나, 비용문제로 거의 사용하지 않는다고 한다.
3) Raid 2
- 현재는 사용하지 않는 Raid level
- bit 단위로 스트라이핑을 하고, error correction을 위해 Hamming code를 사용한다.
- m+1개의 데이터 데스크와 m개의 패리티 디스크로 구성된다.(즉 N == (m+1) + m )
- 최소 3개의 디스크로 구성 가능하며, 1개의 디스크 에러 시 복구 가능( 2개 이상의 디스크 에러 시 복구 불가능)
4) Raid 3
- 현재 사용하지 않는 Raid level
- byte 단위로 스트라이핑하고, error correction을 위해 패리티 디스크를 1개 사용한다.
- 용량 및 성능이 단일 디스크 대비 (N-1)배 증가한다.(패리티 디스크 1개를 사용하기 때문에 디스크 개수 N에서 -1을 함)
- Byte단위로 스트라이핑을 하기 때문에 너무 작게 쪼개져 현재는 사용하지 않는다고 한다
- 최소 3개의 디스크로 구성이 가능하며, 1개의 디스크 에러 시 복구 가능하다.(2개 이상의 디스크 에러 시 복구 불가능)
5) Raid 4
- 현재는 (거의) 사용하지 않는 Raid level
- Block 단위로 스트라이핑을 하고, error correction을 위해 패리티 디스크를 1개 사용한다
- 용량 및 성능이 단일 디스크 대비 (N-1)배 증가한다.(Raid 3가 동일한 이유)
- 최소 3개 디스크로 구성이 가능하며 1개의 디스크 에러 시 복구 가능하다.(2개 이상의 디스크 에러 시 복구 불가능)
- Block 단위로 스트라이핑 하는 것은 Raid 5, Raid 6와 동일하지만, 패리티 코드를 동일한 디스크에 저장하기 때문에, 패리티 디스크의 사용량이 높아 해당 디스크의 수명이 줄어든다고 한다. → 이를 개선한 것이 Raid 5
6) Raid 5
- 제일 사용 빈도가 높은 Raid level
- Block 단위로 스트라이핑을 하고, error correction을 위해 패리티를 1개 디스크에 저장하는데, 패리티 저장하는 디스크를 고정하지 않고 매 번 다른 디스크에 저장한다.
- 용량 및 성능이 단일 디스크 대비 (N-1)배 증가한다
- 최소 3개 디스크로 구성이 가능하며, 1개의 디스크 에러 시 복구 가능하다(2개 이상의 디스크 에러 시 복구 불가능)
- Raid 0에서 성능, 용량을 조금 줄이는 대신 안정성을 높인 Raid level 이라고 보면 된다.
7) Raid 6
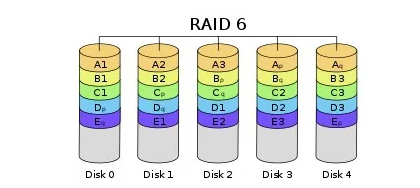
- Raid 5에서 성능, 용량을 좀 더 줄이고, 안정성을 좀 더 높인 Raid level
- Block 단위로 스트라이핑을 하고, error correction을 위해 패리티를 2개의 디스크에 저장하는데, 패리티 저장하는 디스크를 고정하지 않고, 매 번 다른 디스크에 저장한다.
- 용량 및 성능이 단일 디스크 대비 (N-2)배 증가한다.(패리티 저장하는 디스크 2개 제외)
- 최소 4개의 디스크로 구성가능하며, 2개의 디스크 에러 시 복구 가능하다.(3개 이상의 디스크 에러 시 복구 불가능)
- 안정성을 높여야 하는 서버 환경에서 주로 사용한다.
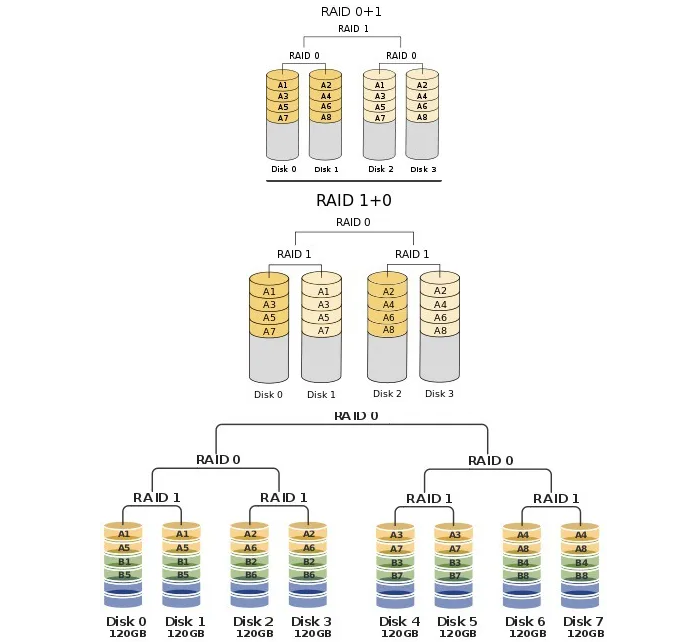
4. Nested Raid (중첩 Raid)
- Nested Raid는 Standard Raid를 여러 개 중첩하여 사용한다.(즉, 복수의 Standard Raid를 또 Raid로 묶는다.)
- 예를 들어, 2개의 Raid 0을 Raid 1로 묶으면 Raid 0+1 혹은 Raid 01 2개의 Raid 1을 Raid 0으로 묶으면 Raid 1+0 혹은 Raid 10
- 극단적으로 2개의 Raid 1을 묶은 Raid 0 2개를 Raid 0으로 묶는 경우도 있다고 한다. Raid 10+0
728x90
320x100